Related Work
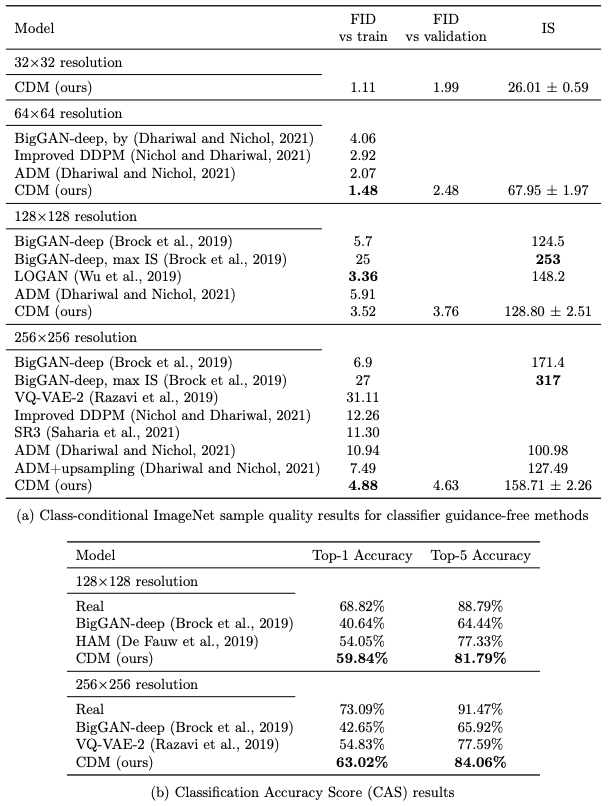
Concurrently, Dhariwal and Nichol showed that their diffusion models, named ADM, also outperform GANs on ImageNet generation. ADM achieves this result using classifier guidance, which boosts sample quality by modifying the diffusion sampling procedure to simultaneously maximize the score of an extra image classifier. As measured by FID score, ADM with classifier guidance outperforms our reported results, but our reported results outperform ADM without classifier guidance.
Our work is a demonstration of the effectiveness of pure generative models, namely cascaded diffusion models without the assistance of extra image classifiers. Nonetheless, classifier guidance and cascading are complementary techniques for improving sample quality, and a detailed investigation of how they interact is warranted.
 Selected generated images from our 256x256 class-conditional ImageNet model.
Selected generated images from our 256x256 class-conditional ImageNet model.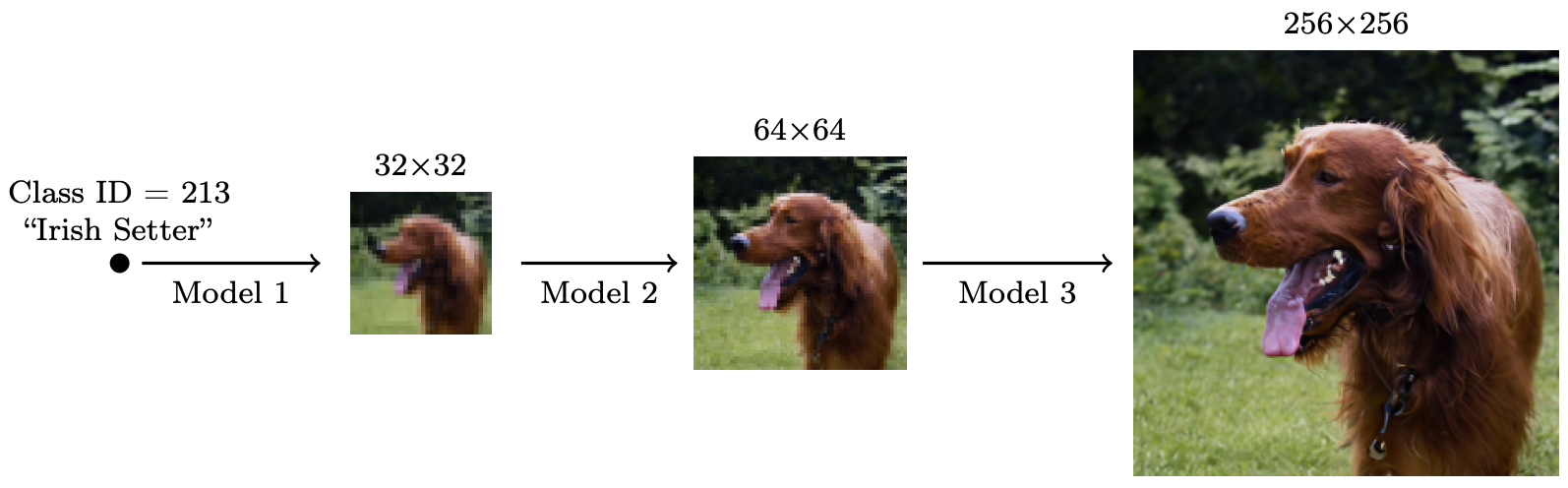 A cascaded diffusion model comprising a base model and two super-resolution models.
A cascaded diffusion model comprising a base model and two super-resolution models.